PROFDINFO.COM
Votre enseignant d'informatique en ligne
Gestion de processus
Programme vs processus
Un programme, également appelé logiciel, application ou exécutable, est un fichier binaire contenant des instructions en langage machine que le processeur peut comprendre. Tout fichier qui peut être exécuté sur l'ordinateur est un programme. Toutefois, seuls les programmes qui sont en exécution sont appelés des processus.
En effet, un processus est un programme qui est en train d'être exécuté par l'ordinateur. Lorsqu'un programme devient un processus, il est chargé en mémoire vive dans une zone spécifique, puis le processeur suivra ses instructions une par une.
Comme tout système récent (et même moins récent!) est maitenant multitâches, cela signifie que le processeur doit être capable d'exécuter plusieurs processus en même temps. C'est un des rôles du système d'exploitation que de permettre cela, et de gérer les ressources afin que ça puisse se faire harmonieusement.
Premièrement, tout processus se verra donc attribuer un numéro, appelé Process ID (ou PID) par le système d'exploitation. Ce numéro est unique sur le système au moment où il est attribué, mais un même PID pourra être réutilisé éventuellement lorsqu'il redevient disponible (parce qu'un processus a terminé son exécution). Le PID permet d'identifier le processus sans ambiguïté sur le système et est laissé à la totale discrétion du système d'exploitation.
Ordonnancement
Un processeur classique ne peut physiquement pas réaliser plus qu'une opération à la fois. Un processeur double coeur peut généralement exécuter deux instructions à la fois, mais même avec un quadruple coeur, on s'entend qu'un usage normal d'un ordinateur demandera au processeur plus d'opérations qu'il est capable d'en exécuter à tout moment.
La seule façon de s'en sortir alors est de fonctionner par tranches de temps: le processeur va passer un certain temps à exécuter un processus, puis il le mettra en attente et passera un peu de temps à en exécuter un autre, et ainsi de suite. Sur un ordinateur assez puissant pour l'usage qu'on en fait, on aura l'impression que tous ces programmes sont exécutés en parallèle, comme si chacun d'eux disposait de son propre processeur. L'illusion est particulièrement convaincante lorsqu'on exécute plusieurs programmes qui ne font pas grand-chose (comme un fureteur Internet, un logiciel de chat, un lecteur mp3 et un traitement de texte) - dans ce cas-là, les processus qui sont mis en attente ne feraient probablement rien de leur temps de toute façon.
Évidemment, si l'usage devient plus intense (par exemple, si on compile du code complexe, que l'on fait du montage vidéo, de l'animation 3D ou que l'on joue à un jeu récent), le processeur ne fournit plus aussi aisément à la demande et chaque processus attend alors qu'il aimerait bien continuer à traiter de l'information.
C'est un des rôles fondamentaux du système d'exploitation que de régir l'ordonnancement: l'ordre dans lequel les processus seront traités et quand chacun pourra utiliser le CPU. Un système multitâches est comme un appartement rempli de colocs mais avec une seule salle de bains...
Algorithmes d'ordonnancement sans réquisition (coopératif)
Sur les premiers systèmes (MS-DOS, Windows 3.1, MacOS avant la version 9), un algorithme sans réquisition était utilisé. Le principe est fort simple: chaque processus décide lui-même quand il "redonne la main" au système d'exploitation, qui pourra alors la donner à un autre processus. Typiquement, un processus rendait la main au SE lorsqu'il avait terminé, ou lorsqu'il était en attente sur une opération d'entrée/sortie.
Ce genre d'algorithme a des désavantages bien évidents: le CPU peut être monopolisé par un processus qui ne rend jamais la main, au détriment de tous les autres qui semblent alors "gelés", et si jamais un processus gèle avant de remettre la main, tout le système gèle et on doit redémarrer la machine.
Algorithmes d'ordonnancement avec réquisition (préemptif)
Les SE modernes utilisent évidemment un système un peu plus évolué: c'est le système d'exploitation qui a le pouvoir de déterminer qui utilise le processeur et pour combien de temps. Il peut également interrompre un processus pour donner le processeur à quelqu'un d'autre.
Il existe plusieurs méthodes pour ordonnancer les processus. La plus simple est d'allouer une tranche de temps fixe à chaque processus. Lorsque le temps est écoulé, on lui enlève la main et on passe au suivant. Si jamais un processus bloque en entrée/sortie ou termine avant le temps, la tranche est interrompue à ce point et on change de processus.
Plus la tranche de temps est longue, plus le temps d'attente est long pour l'usager. À l'inverse, plus le temps d'attente est court, plus le système perd en performances. En effet, passer d'un processus à l'autre demande de sauvegarder le contexte d'exécution du processus (l'état des registres du processeur et sa zone de mémoire vive), pour recharger le contexte d'un autre. Le coût de ces opérations, lorsqu'elles sont trop souvent répétées, ralentit l'ordinateur. Il faut donc faire un compromis acceptable.
Optionnellement, un système d'exploitation peut utiliser une notion de priorité pour déterminer l'importance des processus. Certains peuvent être plus importants que d'autres et bénéficier de plus de temps de CPU. Il est normalement possible pour l'administrateur du système de modifier la priorité d'un processus donner pour le faire passer avant les autres ou, possiblement, pour le rendre moins prioritaire et ainsi permettre de faire autre chose en même temps sans être ralenti.
Un système de priorités peut être statique ou dynamique. Lorsqu'il est statique, la priorité d'un processus ne changera que si l'usager en fait la demande. Un système de priorités dynamqiue est capable de déterminer la priorité à assigner à un processus en fonction de son comportement et il peut même l'ajuster si son comportement change. Par exemple, si un processus est souvent en attente d'entrées/sorties, sa priorité montera afin qu'il ait rapidement accès au processeur lorsqu'il en a finalement besoin.
Le cas de Windows
Windows utilise un algorithme d'ordonnancement complexe appelé Multilevel feedback queue (files d'attente à plusieurs niveaux). Le principe est le suivant:
- Un nouveau processus est placé à la fin de la file d'attente la plus prioritaire (on l'appellera la "file de haut niveau").
- Éventuellement, il arrive à la tête de la file - chaque processus sur cette file reçoit une tranche de temps (on dit aussi un quantum) courte.
- S'il ne peut pas terminer pendant sa tranche de temps, il est rétrogradé et sera placé à la fin de la file d'en dessous. Cette dernière fonctionne avec des quantums plus longs (donc ça prend plus de temps pour arriver au bout, mais une fois rendu, on a plus de temps pour terminer ce qu'on a à faire).
- Une fois au bout de la deuxième file, il reçoit son quantum. S'il ne termine pas, il sera rétrogradé à nouveau.
- Le tout continue ainsi jusqu'à ce que le processus termine ou qu'il arrive à la dernière file.
- Si le processus bloque sur une entrée/sortie, il est promu à la file d'au-dessus.
En plus de tout ceci, Windows utilise un système à 6 priorités de processus:
- Basse
- Inférieure à la moyenne
- Moyenne
- Supérieure à la moyenne
- Haute
- Temps réel
Un processus plus prioritaire passera avant les processus moins prioritaires qui sont devant lui dans sa file. Toutefois, la dernière file ne tient plus compte de la priorité et utilise un algorithme de type Round Robin, pendant lequel chaque processus reçoit une tranche de temps égale pour chacun et où personne ne peut dépasser personne.
Les arborescences de processus
Un processus peut très bien en démarrer un autre. Par exemple, vous êtes sur Internet et vous téléchargez un mp3. Votre lecteur mp3 démarre et le lit. Le lecteur mp3 a été lancé par le navigateur Internet. On dira que le navigateur est le processus parent du lecteur mp3.
Sous Windows, une fois que le parent a lancé l'enfant, il n'y a plus de lien bien défini entre les deux. L'enfant devient automatiquement indépendant, s'exécute dans sa propre zone mémoire, obtient sa propre priorité et peut exister sans son parent. Le fait d'arrêter le processus parent n'arrête pas nécessairement le processus enfant. Vous verrez plus tard que c'est différent sous Linux.
Le multithreading
Windows est un système multitâches et multithreads. On peut traduire "thread" par fil d'exécution (mais on utilise très souvent le terme anglophone). Un thread est le résultat d'une division d'un processus. En effet, lorsqu'un processus est exécuté, le système crée automatiquement son premier thread, appelé le thread primaire. Ce thread pourra ensuite en créer d'autres, qui pourront eux aussi en créer d'autres, afin de permettre un parallélisme interne au programme: c'est comme un deuxième niveau de subdivision du temps CPU.
Chaque thread à l'intérieur du processus a lui aussi sa priorité, gérée par le processus. Un thread peut recevoir une des 7 priorités suivantes:
- Inactif (idle)
- Basse
- Inférieure à la moyenne
- Moyenne
- Supérieure à la moyenne
- Haute
- Critique
Comme ces priorités sont gérées par le processus, qui a lui même une priorité au niveau du SE, Windows accordera donc une valeur différente à chaque thread selon ces deux niveaux de priorité. La valeur finale pourra aller de 1 (très peu prioritaire) à 31 (très prioritaire):
Priorité du processus |
||||||
Priorité du thread |
Temps réel |
Haute |
Supérieure |
Moyenne |
Inférieure |
Basse |
Critique |
31 |
15 |
15 |
15 |
15 |
15 |
Haute |
26 |
15 |
12 |
10 |
8 |
6 |
Supérieure |
25 |
14 |
11 |
9 |
7 |
5 |
Moyenne |
24 |
13 |
10 |
8 |
6 |
4 |
Inférieure |
23 |
12 |
9 |
7 |
5 |
3 |
Basse |
22 |
11 |
8 |
6 |
4 |
2 |
Inactif |
16 |
1 |
1 |
1 |
1 |
1 |
Vous apprendrez comment faire des programmes multithread plus tard au cours de votre formation. C'est un outil très puissant!
Les handles
Dans le monde Windows, tout est un objet. Un objet peut être vu comme un ensemble de données qui décrivent quelque chose, ainsi que des fonctions pour manipuler ces données, le tout encapsulé dans une seule structure indépendante et autonome. Vous aurez l'occasion de voir en détail le principe des objets tout au long de votre formation.
Pour l'instant, il est tout simplement pratique de savoir que chaque processus, chaque thread, chaque périphérique matériel est encapsulé dans un objet. Chaque objet a un handle (traduction littérale: une poignée) permettant d'interagir avec lui. Lorsque vous voulez interagir avec une quelconque composante logicielle ou matérielle de Windows, vous devez utiliser son handle.
Les libriaires dynamiques (dll)
Windows utilise beaucoup le concept de librairies dynamiques (Dynamic link libraries, ou dll, parfois appelés modules). Un fichier .dll est un fichier de code qui contient différentes classes ou fonctions que n'importe quel programme peut utiliser à sa guise sans devoir les recoder à partir de zéro. Ce principe de réutilisation est bien pratique et vous permet déjà de faire des racines carrées dans vos programmes sans devoir comprendre et coder l'algorithme d'une racine carrée.
Éventuellement un très grand nombre de dll peuvent être accumulées sur un sytème et plusieurs processus peuvent utiliser plusieurs de ces dll. Il est toujours possible qu'un virus se camoufle sous forme de dll et qu'on ne puisse pas aisément savoir qui lui fait référence au juste.
Gérer les processus
L'outil principal que Windows nous donne pour gérer les processus est nommé le gestionnaire des tâches. Il permet de voir tous les processus en exécution, ainsi que quelques informations sur chacun d'eux, puis de modifier leur priorité ou carrément de les éliminer. On peut invoquer le gestionnaire des tâches de plusieurs façons différentes:
- En cliquant avec le bouton de droite sur la barre des tâches, puis en choisissant l'option appropriée du menu contextuel;
- En faisant Ctrl-Alt-Del et en choisissant l'option appropriée dans le menu (certaines configurations n'affichent pas de menu et appellent alors directement le gestionnaire);
- En faisant Ctrl-Maj-Esc.
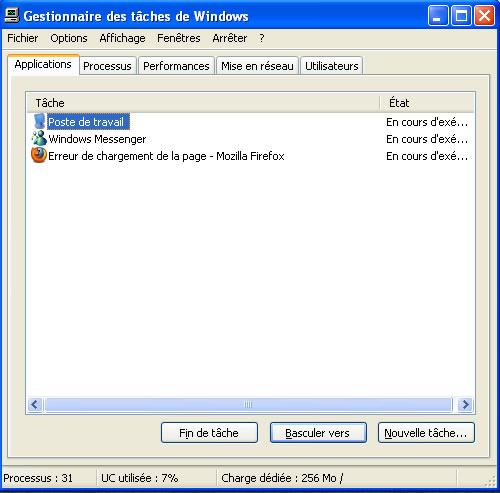
L'onglet Applications montre toutes les applications qui ont été démarrées sur l'ordinateur. On parle d'applications démarrées explicitement par l'usager - cela n'inclut donc pas les applications qui sont démarrées automatiquement par Windows, ni les processus des composantes de Windows lui-même. À partir d'ici, on peut contrôler les applications, soit en les mettant au premier plan, en les réduisant, en les agrandissant ou carrément en les arrêtant. On peut parfois tuer une application qui a "gelé" et qui ne répond plus (mais ça ne fonctionne (étrangement) pas toujours). On peut également atteindre le processus associé à l'application, ce qui nous téléporte à l'onglet suivant.
Cet onglet suivant, c'est l'onglet Processus. Il nous montre tous les processus en ce moment en exécution sur l'ordinateur, peu importe qui les a lancés. On voit quelques informations de base sur chaque processus: l'usager qui l'a démarré (c'est souvent SYSTEM, SERVICE LOCAL ou SERVICE RESEAU, des pseudo usagers gérés par Windows), le pourcentage des capacités du CPU qu'il utilise et la quantité de mémoire utilisée par le processus. On peut aisément ajouter d'autres colonnes à l'affichage pour voir le PID, ainsi que tout un tas d'autres statistiques plus ou moins intéressantes. À partir de cet onglet, on peut terminer un processus ou en changer sa priorité.
Notez qu'il est également possible de terminer l'arborescence du processus. Cela signifie "terminer le processus lui-même, ainsi que tous ses processus enfants, et les enfants de ses enfants, et ainsi de suite". Autrement dit, on tue un processus et toute sa descendance. Quelle violence.
L'onglet Performances montre un diagramme mis à jour en temps réel de l'utilisation du CPU et de la mémoire, ainsi que quelques statistiques sur cette dernière.
L'onglet Mise en réseau nous montre un diagramme similaire pour l'activité de la carte réseau.
L'onglet Utilisateurs nous affiche la liste des utilisateurs connectés à l'ordinateur (ce qui est beaucoup plus utile dans le cas d'un serveur que d'un poste client).
Un gestionnaire plus détaillé
La compagnie SysInternals (une propriété de Microsoft) a mis au point l'excellent logiciel ProcessExplorer, logiciel totalement gratuit. Il permet de voir tous les processus sous forme d'arborescence, de voir beaucoup plus de détails sur ceux-ci, d'obtenir encore plus de statistiques et de trouver aisément quel(s) processus utilisent un fichier ou un dll particulier.
Gestion des processus en mode console
L'interpréteur de commandes de Windows (cmd.exe) nous offre deux commandes fort utiles pour faire la gestion des processus en mode texte. Pourquoi fonctionner en mode texte? Plusieurs raisons:
- Parce que c'est souvent plus rapide si on connaît les commandes;
- Parce que ça permet l'automatisation de telles commandes via un script;
- Parce que ça permet d'être exécuté à distance (et donc de gérer les processus d'un autre ordinateur);
- Parce qu'on peut filtrer la liste pour obtenir seulement ce qui nous intéresse;
- Parce que ça peut faire plus que le gestionnaire des tâches de Windows et que ça ne nécessite aucune installation.
Les deux commandes sont tasklist et taskkill. Elles fonctionnent toutes les deux à peu près de la même façon. tasklist sert à afficher les processus qui correspondent à nos critères et taskkill à les tuer. Faites tasklist /? et taskkill /? pour accéder à l'aide sur ces commandes.
Voici quelques pistes pour vous guider:
On utilise les commandes texte en allant dans la console texte, aussi appelée shell ou interpréteur de commandes. Pour l'ouvrir, il suffit d'aller dans le menu Démarrer, de choisir "Exécuter" et de taper cmd. La fenêtre ressemble à l'ancien DOS (l'ancêtre de Windows): fond noir, police de caractères de taille fixe grise, utilisation de la souris peu évoluée.
On peut y taper des commandes de toutes sortes (on y viendra plus tard). Pour l'instant les commandes se limiteront à tasklist et taskkill.
Ces commandes peuvent accepter des paramètres, c'est-à-dire des informations qu'on tapera après le nom de la commande pour modifier son comportement. La grande majorité de ces paramètres sont ce qu'on appelle souvent des switches (en français: modificateurs). Une switch est formée d'une barre oblique (/) suivie d'une ou plusieurs lettres correspondant à quelque chose. Ces switches modifient le comportement de la commande et permettent d'en faire ce que l'on veut.
Par exemple, tasklist tout court nous affiche la liste des processus en cours d'exécution. tasklist /m affiche la même liste, mais ajoute une colonne "modules" montrant les librairies (.dll) utilisées par chaque processus. tasklist /v est un mode "verbeux" (verbose) qui affiche plus d'information pour chaque processus.
La switch /?, comme dans tasklist /?, permet d'afficher l'aide sur la commande, qui contient une liste des switches possibles et quelques exemples.
Certaines switches sont plus complexes et demandent qu'on fournisse en plus une information quelconque. C'est le cas de /fi qui permet de filtrer les processus affichés selon certains critères. Pour l'utiliser, on doit la faire suivre d'un filtre, entre guillemets, qui décidera de ce qui sera affiché. Un filtre est composé d'un nom de colonne, d'un opérateur relationnel (comme plus petit, égal, plus grand) et d'une valeur. Les processus dont le critère est respecté seront affichés et pas les autres.
Il faut savoir que les opérateurs relationnels sont ici représentés par des codes de deux lettres qui correspondent au mot en anglais. Donc:
- eq signifie equals (égal)
- ne signifie not equal (pas égal)
- lt signifie lesser than (plus petit que)
- gt signifie greater than (plus grand que)
- le signifie lesser than or equal (plus petit ou égal)
- ge signifie greater than or equal (plus grand ou égal)
Il faut aussi savoir que dans le monde tasklist/taskkill, les librairies (.dll) sont appelés des modules et les exécutables (donc les processus) sont appelés des images (donc imagename signifie nom de processus).
Ne confondez pas la switch /u et le nom de colonne username à utiliser dans un filtre (avec /fi). /u sert à s'authentifier sur un ordinateur distant. username sert à filtrer les processus pour n'afficher que ceux qui correspondent à un usager donné.
Finalement, il existe toujours la possibilité de rediriger la sortie d'une commande (ce qui est normalement affiché à l'écran) dans un fichier texte. Cette possibilité est fournie par le système d'exploitation (en fait, par son interpréteur de commandes) et est donc utilisable pour n'importe quelle commande -- ce n'est pas tasklist qui implémente cette fonctionnalité, c'est l'interpréteur de commande. Le principe est simple: on écrit la commande qu'on veut et on la fait suivre du symbole > puis du nom d'un fichier. La commande sera alors exécutée normalement et tout ce qui aurait été envoyé à l'écran sera plutôt envoyé dans le fichier donné. Vous ne verrez donc rien du tout à l'écran:
commande > fichier.txt
Il est possible de jouer avec le formatage de la sortie grâce à la switch /fo, que vous faites suivre d'un code pour le format voulu. Ceci change le format à l'écran, mais comme la sortie peut être redirigée dans un fichier, ça peut aussi changer le format dans le fichier!
Exercices
Les exercices suivants ont pour but de vous familiariser avec ces commandes texte et également à vous faire fouiller dans l'aide pour en comprendre le principal. Ne vous gênez pas pour expérimenter! N'oubliez pas qu'il est possible que certaines commandes ne puissent pas être exécutées sur votre ordinateur à cause des permissions de votre compte. Si c'est le cas, indiquez tout de même la commande qui serait supposée réaliser la tâche demandée.
Indiquez les commandes nécessaires pour:
Afficher à l'écran la liste des processus présentement en cours d'exécution sur votre ordinateur:
Envoyer dans un fichier texte la liste des processus présentement en cours d'exécution sur votre ordinateur ainsi que les DLL qui sont utilisés par chaque processus:
Afficher à l'écran la liste des processus qui utilisent présentement le DLL userenv.dll:
Afficher à l'écran la liste des processus qui ne répondent plus (notez la syntaxe qui serait supposée être correcte selon la documentation. Défi pour les pros de la recherche: cette fonctionnalité est boguée -- pouvez-vous trouver ce qu'il faut faire pour arriver à nos fins malgré tout?):
Afficher à l'écran la liste des processus qui ont utilisé 10 minutes de temps CPU ou plus depuis leur démarrage:
Afficher à l'écran la liste des processus qui utilisent plus d'un meg de mémoire:
Afficher la liste des processus démarrés par l'usager georges:
Afficher la liste de tous les processus qui n'ont pas été lancés par le système:
Créer un fichier CSV (Comma Separated Values) contenant la liste de tous les processus en cours sur l'ordinateur, sans la ligne d'entête:
Tuer le processus 2323 sur votre système:
Tuer toutes les instances d'Internet Explorer qui roulent en ce moment sur l'ordinateur de votre voisin (le nom de l'ordinateur est visible dans les propriétés du Poste de travail) -- notez que la commande ne fonctionnera pas si vous n'êtes pas administrateur, donc pas dans le P113!:
Tuer d'un seul coup tous les processus qui ne répondent plus sur votre ordinateur:
Tuer d'un seul coup tous les processus qui utilisent le DLL bigvirus.dll:
Tuer en une seule commande les processus numéro 1212, 2323, 3434 ainsi que tous les processus enfants qu'ils auraient pu générer:
À quoi sert l'option /f de la commande taskkill en fin de compte?